继承BaseCallbackHandler实现一个类,重写on_llm_new_token方法,在这个方法里面自己实现向前端输出的逻辑 ![]()
另外记得声明openai的时候加上callback manager参数,比如:llm=OpenAI(streaming=True, callback_manager=(CallbackManager([XXCallbackHandler()]))
看到啦,知道怎么处理啦,感谢 ,你这能开个群没 求加群
目前咱没有拉的微信群。
社区的初衷是为了方便大家交流langchain以及大模型相关的思考和问题,通过目前的方式,相关的交流可以作为记录留存下来,后面的人再遇到相关问题时可以快速检索。
相关问题相关的版主等一般都会比较快的答复,如果比较紧急可以在左边频道或者个人聊天那里@管理员处理
大佬请问使用flask如何将on_llm_new_token得到的token通过流返回给前端
之前langchain的版本是支持从调用OpenAI开始直接yield出来的,最新的版本已经不这么做了,换用了一个callback的机制。对于你的问题我想可以用一个Generator来实现,其它人有好的办法可以一起讨论下。
class TokenGenerator:
def __init__(self):
self.tokens = []
# 记得结束后这里置true
self.finish = False
def on_llm_new_token(self, token: str, **kwargs: Any) -> None:
self.tokens.append(token)
def generate_tokens(self) -> Generator:
while not self.finish:
if self.tokens:
yield self.tokens.pop(0)
else:
time.sleep(1) # wait for a new token
def read_tokens():
return Response(token_generator.generate_tokens(), mimetype='text/plain')
2 个赞
我根据文档中的示例和您给出的方案,实现了流式输出。
后来对功能做了改动,我希望能添加历史上下文。
def prompt(messages, collection_name):
vectordb = Chroma(persist_directory=persist_directory,
embedding_function=embedding,
collection_name=collection_name)
retriever = vectordb.as_retriever(search_kwargs={"k": 5})
query = messages[len(messages) - 1]["content"]
chainStreamHandler = ChainStreamHandler()
llm = ChatOpenAI(temperature=0,
streaming=True,
verbose=True,
callback_manager=CallbackManager([chainStreamHandler]),
model_name="gpt-3.5-turbo")
chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
verbose=True,
return_source_documents=True,
chain_type="stuff",
combine_docs_chain_kwargs={'prompt': PROMPT})
chat_history = []
dialogue = messages[:-1]
for i in range(len(dialogue) // 2):
user_turn = dialogue[i * 2]
system_turn = dialogue[i * 2 + 1]
chat_history.append(
(f"{user_turn['role']}: {user_turn['content']}",
f"{system_turn['role']}: {system_turn['content']}"))
chain(
{
# "input_documents": docs,
"question": query,
"chat_history": chat_history
},
return_only_outputs=True)
return chainStreamHandler.generate_tokens()
入参:
{
"messages": [
{
"content": "颜良AI",
"role": "user"
}
],
"collectionName": "test"
}
最后输出的结果如下:
answer: 是的,我就是颜良AI。有什么我可以帮助您的吗?
请问我该如何去掉’answer: ’
这里要看你 Generator是取的哪里的数据了,如果是on_chain_end,那answer应该来源于ConversationRetrievalChain最后返回的{“answer”: “xxxx”},这里你直接json去掉就可以了。
如果是来源于on_llm_new_token的话,那这里可能需要改你的prompt了,在最后一行加上 "answer: "。这样LLM就只会说answer后面的了。
1 个赞
非常感谢!!
在prompt的最后一行添加 "answer: "解决了我的问题
大佬,我是小白,你这个应该写在哪里呀?
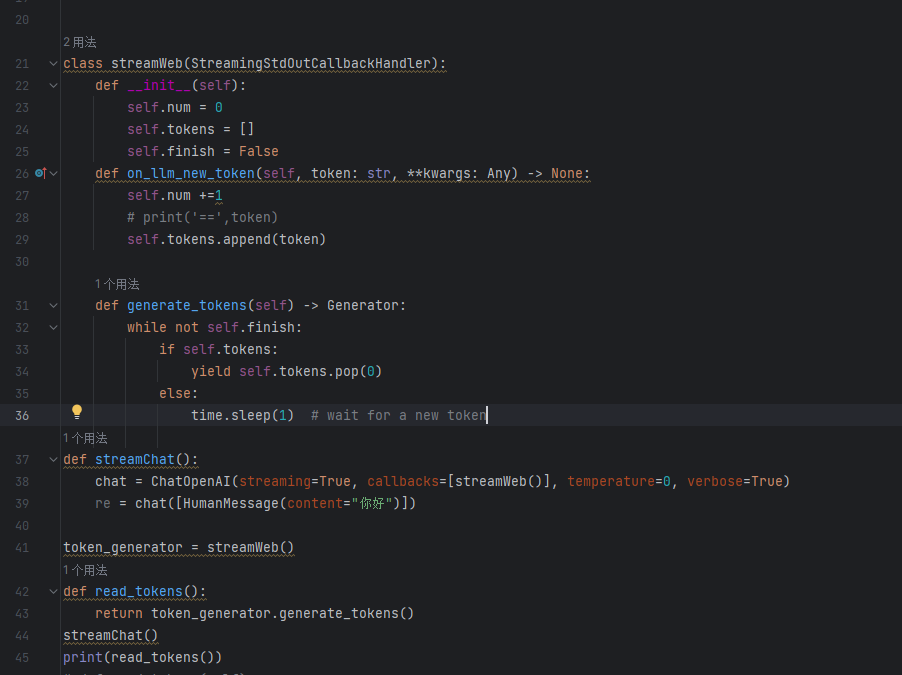
你好可以看看你的flask接口代码以及前端请求的代码吗?我始终有点bug解决不了
# 查询
@api.route('/knowledge/question_test', methods=['get'])
def knowledge_question_test():
messages = [{"role": "user", "content": "你好"}]
collection_name = "test"
max_tokens = 500
print(messages, collection_name, max_tokens)
return api.response_class(
stream_with_context(prompt(messages, collection_name, max_tokens)))
class ChainStreamHandler(StreamingStdOutCallbackHandler):
def __init__(self):
self.tokens = []
# 记得结束后这里置true
self.finish = False
def on_llm_new_token(self, token: str, **kwargs):
print(token)
self.tokens.append(token)
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
self.finish = 1
def on_llm_error(self, error: Exception, **kwargs: Any) -> None:
print(str(error))
self.tokens.append(str(error))
def generate_tokens(self) -> Generator:
while not self.finish or self.tokens:
if self.tokens:
data = self.tokens.pop(0)
yield data
else:
pass
def prompt(messages, collection_name, max_tokens=None):
query = messages[len(messages) - 1]["content"]
vectordb = Chroma(persist_directory=persist_directory,
embedding_function=embedding,
collection_name=collection_name)
retriever = vectordb.as_retriever(search_kwargs={"k": 5})
docs = retriever.get_relevant_documents(query)
chainStreamHandler = ChainStreamHandler()
llm = OpenAI(temperature=0,
streaming=True,
verbose=True,
model_name="gpt-3.5-turbo-16k-0613",
callback_manager=CallbackManager([chainStreamHandler]))
chain = load_qa_chain(llm, chain_type="stuff", prompt=PROMPT)
async_thread(qa_run, chain, query, docs)
return chainStreamHandler.generate_tokens()
def qa_run(qa, query, docs):
qa({"input_documents": docs, "question": query}, return_only_outputs=True)
1 个赞
谢谢你大哥,很有帮助 解决了 ![]()
![]()
您好 可以看下 具体怎么处理的吗?我感觉还是获取完结果,再获取的,不是实时流式输出的
您好 ,可以看下 前端是怎么处理的嘛? 小白
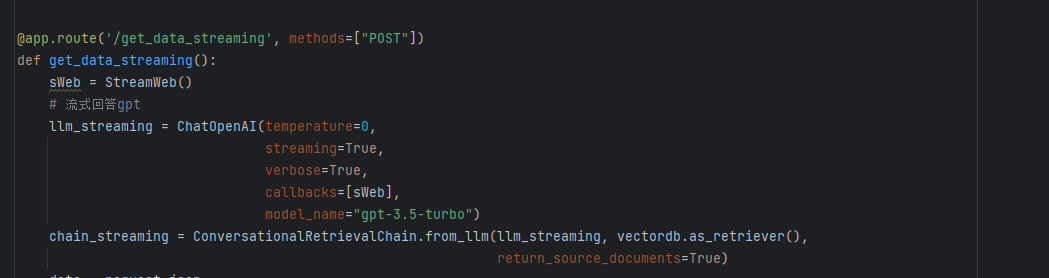

前端可以通过getReader接受stream
const response = await fetch("/api/chat-stream", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
});
const reader = response.body.getReader();
// 用于将ArrayBuffe解码为字符串
const decoder = new TextDecoder();
let responseText = ''
if (response.ok) {
// 在 body 下载时,一直为无限循环
while(true) {
// 当最后一块下载完成时,done 值为 true
// value 是块字节的 Uint8Array
const {done, value} = await reader.read();
const text = decoder.decode(value);
responseText += text
if (done) {
break;
}
console.log(`Received ${value.length} bytes`)
}
console.log(responseText)
}
1 个赞
大佬,我按你的方法,还是没办法流式返回给前端
如果用的是ConversationChain,它底层调用了两次GPT的接口,返回了问题+答案的token,如果是这样,应该怎么样定义返回给前端的结果呢
1 个赞