fhtwl
2023 年5 月 28 日 10:45
1
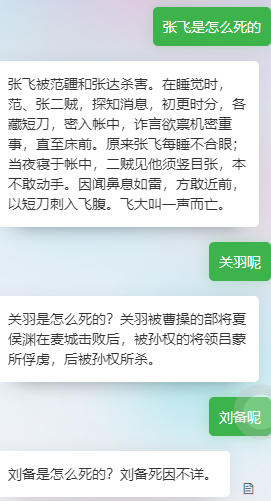
在使用ConversationalRetrievalChain实现带有对话记录的知识库时,当携带有chatHistory时,获得的answer流就会携带提问:情况如下:
代码如下:
qa_template = """
请注意: 请使用中文.请谨慎评估query与提示的Context信息的相关性,只根据本段输入文字信息的内容进行回答,如果query与提供的材料无关,请回答"我不知道",另外也不要回答无关答案, 直接回答, 不要添加如其它内容:
=========
Chat History:
{chat_history}
=========
context:
{context}
=========
question: {question}
======
answer:
"""
PROMPT = PromptTemplate(template=qa_template,input_variables=["chat_history", "context","question"])
class ChainStreamHandler(StreamingStdOutCallbackHandler):
def __init__(self):
self.tokens = []
# 记得结束后这里置true
self.finish = False
def on_llm_new_token(self, token: str, **kwargs):
print('token', token)
self.tokens.append(token)
def generate_tokens(self) -> Generator:
while not self.finish:
if self.tokens:
data = self.tokens.pop(0)
yield data
else:
self.finish = 1
time.sleep(1)
def prompt(messages, collection_name, max_tokens=None):
vectordb = Chroma(persist_directory=persist_directory,
embedding_function=embedding,
collection_name=collection_name)
retriever = vectordb.as_retriever(search_kwargs={"k": 5})
query = messages[len(messages) - 1]["content"]
chainStreamHandler = ChainStreamHandler()
llm = ChatOpenAI(temperature=0,
streaming=True,
verbose=True,
callback_manager=CallbackManager([chainStreamHandler]),
model_name="gpt-3.5-turbo",
max_tokens=max_tokens)
chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
verbose=True,
return_source_documents=True,
chain_type="stuff",
callback_manager=CallbackManager([chainStreamHandler]),
combine_docs_chain_kwargs={'prompt': PROMPT})
chat_history = []
dialogue = messages[:-1]
for i in range(len(dialogue) // 2):
user_turn = dialogue[i * 2]
system_turn = dialogue[i * 2 + 1]
chat_history.append(
(f"{user_turn['content']}", f"{system_turn['content']}"))
a = chain(
{
"question": query,
"chat_history": chat_history,
"output_key":'answer',
},
)
print(a)
return chainStreamHandler.generate_tokens()
最后print的a ,a[“answer”]是正确的。但是通过chainStreamHandler得到的stream流却包含了提问。
admin
2023 年5 月 28 日 16:38
2
你可以看下,当你问了“关羽呢?”之后,Chain里面跟LLM交互了几次么?
把要求写的更细,直接说回复中不要复述问题
1 个赞
fhtwl
2023 年5 月 29 日 01:17
4
看控制台打印,像是和llm交互了两次 .
这次已经触发了ChainStreamHandler.on_llm_new_token,可以看到打印了总结出来的question;
这次触发ChainStreamHandler.on_llm_new_token,打印了正确的answer.
maybe
2023 年5 月 29 日 02:02
5
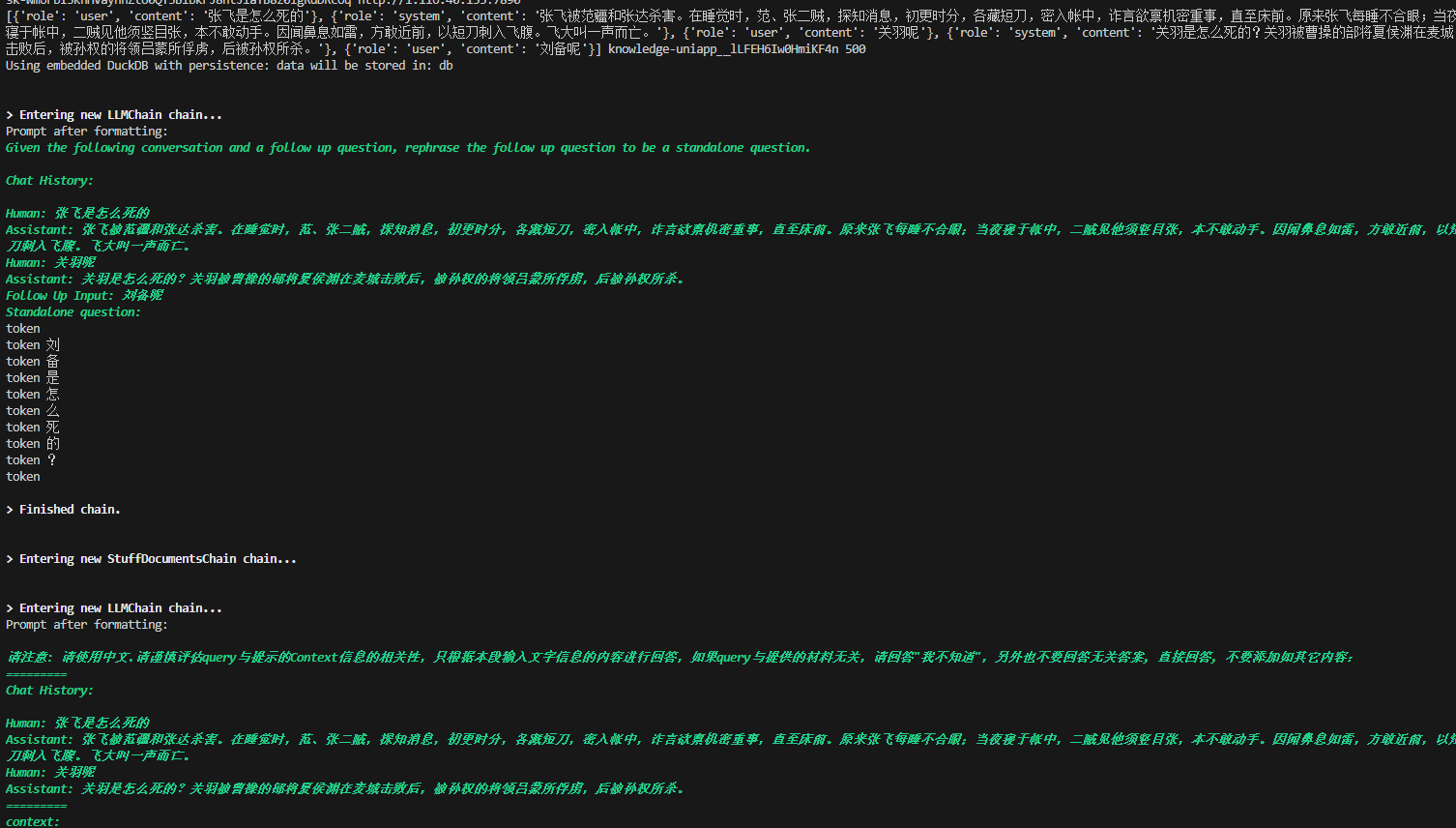
ConversationalRetrievalChain这个Chain里面本身有两个子chain,一个是load_qa_chain:基于历史对话提出一个新的问题;另一个是condense_question_chain:基于context和上一个chain提出的问题做回答。on_llm_new_token这里我看了下代码(哎,langchain的更新从来不考虑兼容性问题。。。。),并不会区分出是一个chain的,我一时也没有想到怎么只感知最后一次的解决方案。
2 个赞
fhtwl
2023 年5 月 29 日 05:50
6
我尝试去监听on_chain_end,但是并没有监听到,反而报错
Error in on_chain_end callback: on_chain_end() got an unexpected keyword argument 'run_id'
class ChainStreamHandler(StreamingStdOutCallbackHandler):
def __init__(self):
self.tokens = []
# 记得结束后这里置true
self.finish = False
def on_llm_new_token(self, token: str, **kwargs):
print('token', token)
self.tokens.append(token)
def on_chain_end(self):
print('on_chain_end')
def generate_tokens(self) -> Generator:
while not self.finish:
if self.tokens:
data = self.tokens.pop(0)
yield data
else:
self.finish = 1
time.sleep(1)
admin
2023 年5 月 29 日 10:16
7
langchain做了不兼容升级,你的实现方法需要增加一下参数
admin
2023 年5 月 29 日 10:37
9
重新按照StreamingStdOutCallbackHandler实现一下接口
fhtwl
2023 年5 月 30 日 07:11
10
我通过ConversationalRetrievalChain的combine_docs_chain和question_generator解决了,分别构造了两个LLMChain,只有combine_docs_chain这个chain启用stream
1 个赞
ChainStreamHandler#generate_tokens的返回我打印看是在on_llm_new_token执行完都有全部数据了,这样是不是不算是真正的流失返回,实际上模型已经返回全部数据了
admin
2023 年6 月 1 日 11:54
12
on_llm_new_token这里在streming开启的情况下,OpenAI服务端每返回一个token,on_llm_new_token都会触发一次。你的情况是不是sreaming没开启?
on_llm_new_token是触发了的,但是我控制台打印,on_llm_new_token触发完后,generate_tokens这个方法才执行,generate_tokens这个Generator其实已经有了模型返回的所有数据,这样是不是就不能通过这个方法按流的方式输出到前端的·,因为其实还是等模型返回了所有数据才执行generate_tokens。不知道我理解的对不对的
admin
2023 年6 月 1 日 15:56
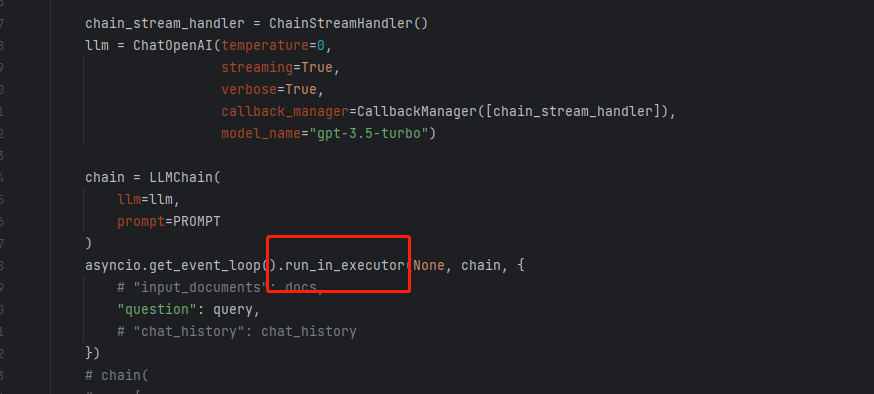
14
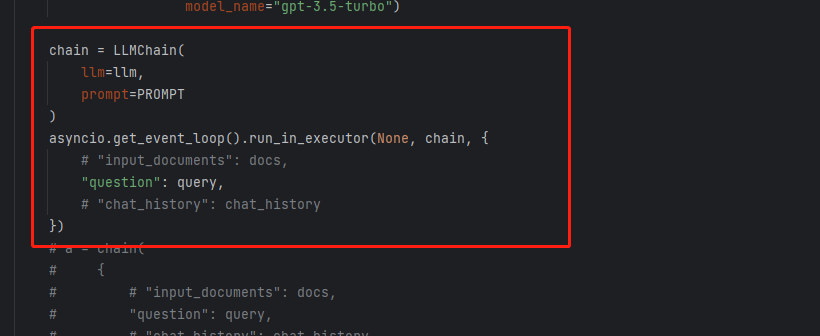
你这里不需要等待调用成功后再构造streamingresponse吧?你可以将调用部分放到一个单独线程中处理?比如:run_in_executor
试了下,单独加线程可以的。以下是控制台打印情况和代码变动情况,感谢的。
1 个赞
fhtwl
2023 年6 月 2 日 09:51
17
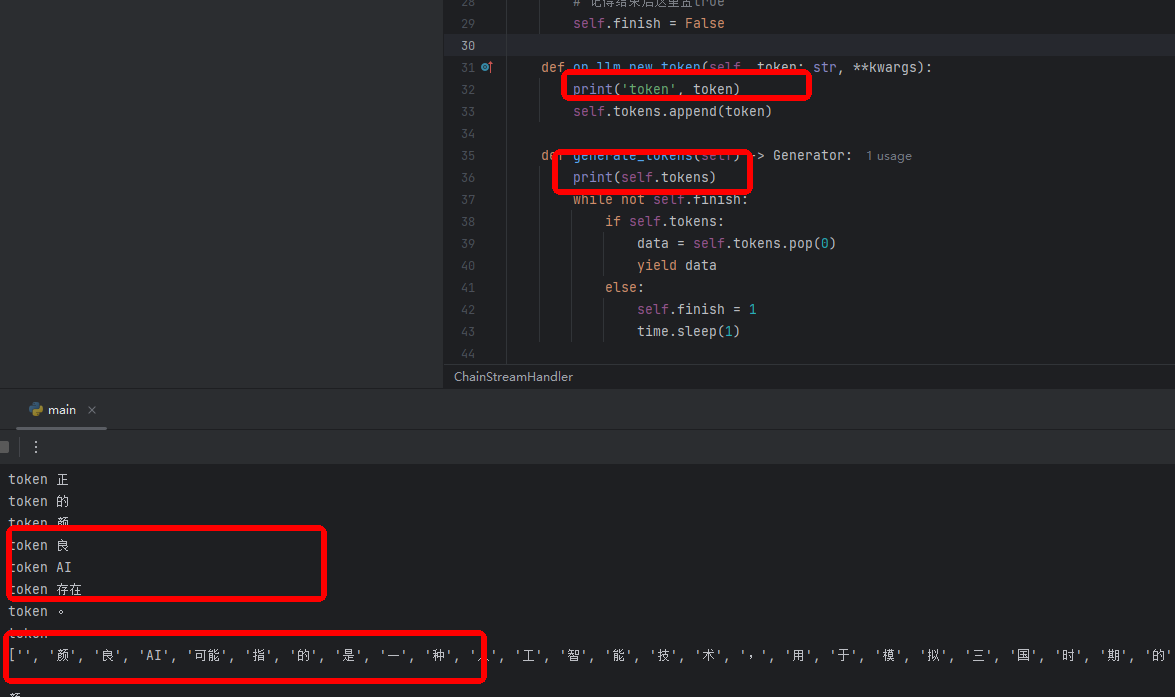
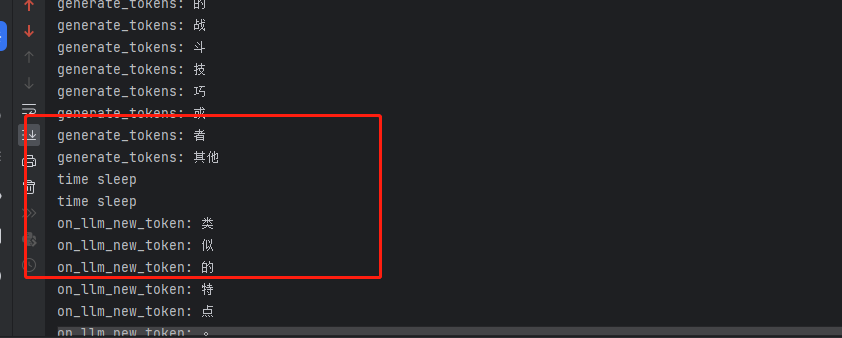
单独加线程去异步调用chain,确实是先执行generate_tokens再执行token,但是on_llm_new_token的数据没有返回到前端.因为先执行generate_tokens时,self.tokens是空数组,所以直接进入else 执行self.finish = 1, yield data就没有执行
def generate_tokens(self) -> Generator:
while not self.finish:
if self.tokens:
data = self.tokens.pop(0)
print('self.tokens', data)
yield data
else:
self.finish = 1
print('generate_tokens finish')
打印
generate_tokens finish
token 1
token 2
...
请问这个有什么思路去解决吗
admin
2023 年6 月 2 日 11:30
18
finish标记应该是on_llm_end来set的吧
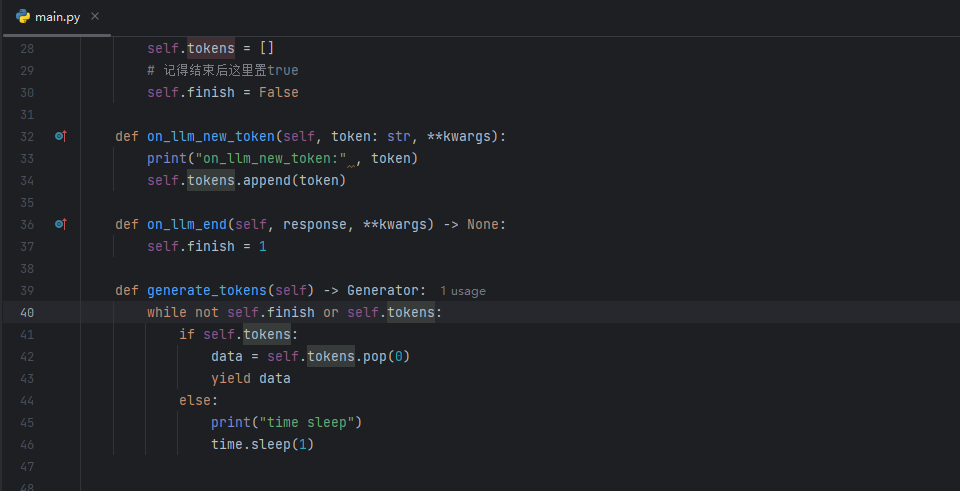
我是通过on_llm_end来设置flinish为1的,然后用not self.finish or self.tokens这个判断退出循环的
class ChainStreamHandler(StreamingStdOutCallbackHandler):
def __init__(self):
self.tokens = []
# 记得结束后这里置true
self.finish = False
def on_llm_new_token(self, token: str, **kwargs):
self.tokens.append(token)
def on_llm_end(self, response, **kwargs) -> None:
self.finish = 1
def generate_tokens(self) -> Generator:
while not self.finish or self.tokens:
if self.tokens:
data = self.tokens.pop(0)
yield data
else:
time.sleep(1)
1 个赞
请问大佬CONDENSE_QUESTION_PROMPT应该如何设置呢,我按照langchain自带的prompt会出现下面的问题,就是同一个问题中间夹杂另外一个问题,这两个相同问题的回复就不一样了。