项目目标
通过LLM的组合创建应用程序万花筒,目前GitHub Star超过2万,
项目架构
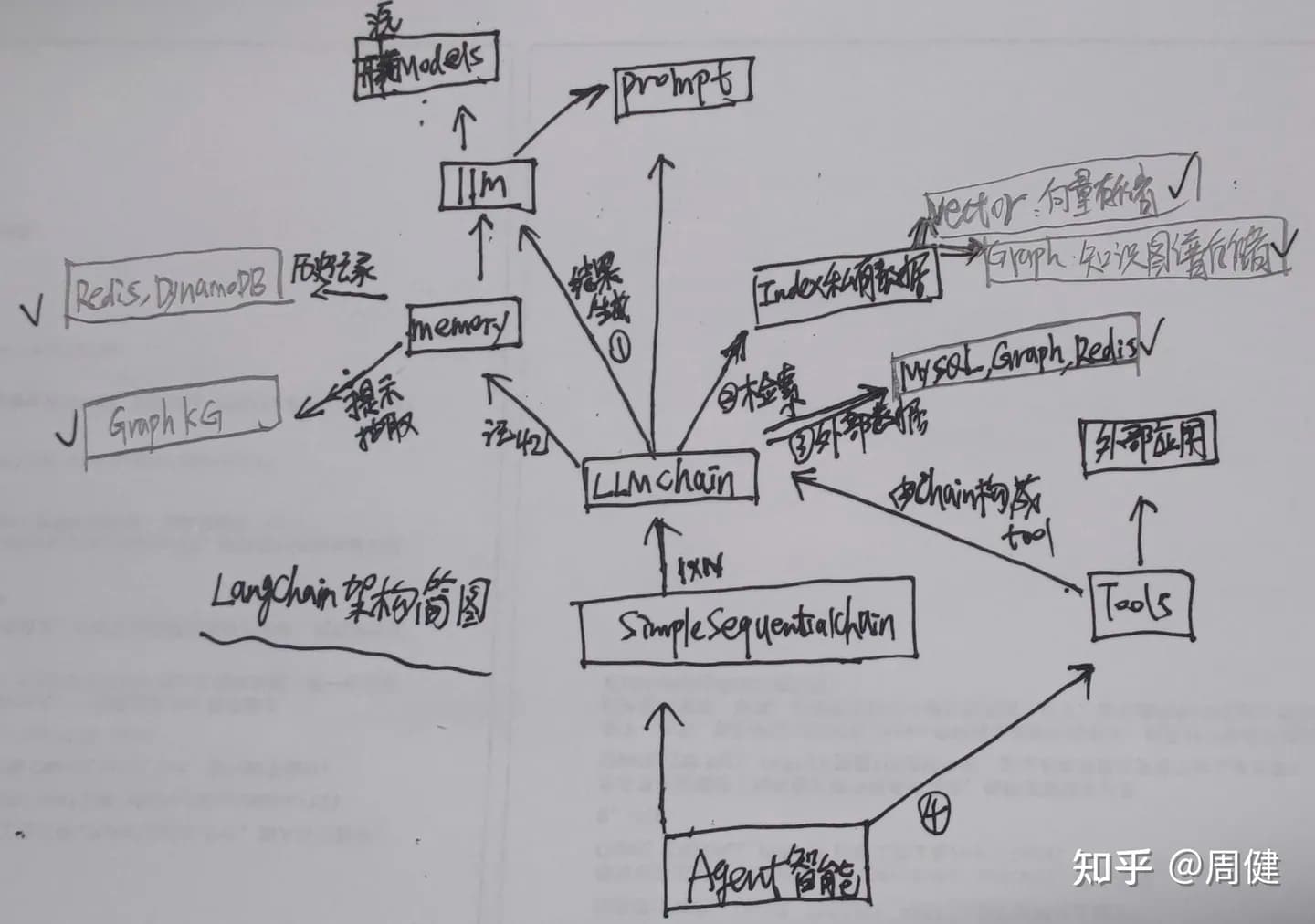
下图中每个部件其实都是一类集合,我们以汽车(人)来类比一个基于LangChain的Agent,核心组件包括:
- 系统发动机(心脏):开源Models以及其封装的LLMS
- 汽油(血液):Prompt
- 方向盘(大脑):Memory
- 前进(创造新应用):LLMChain
- 听流行音乐(链接千行万业):Tools
- 播放珍藏光碟(链接垂直私有领域):Index私有数据
- 开车旅行(开放生态):Agent智能
下面是一张简图:
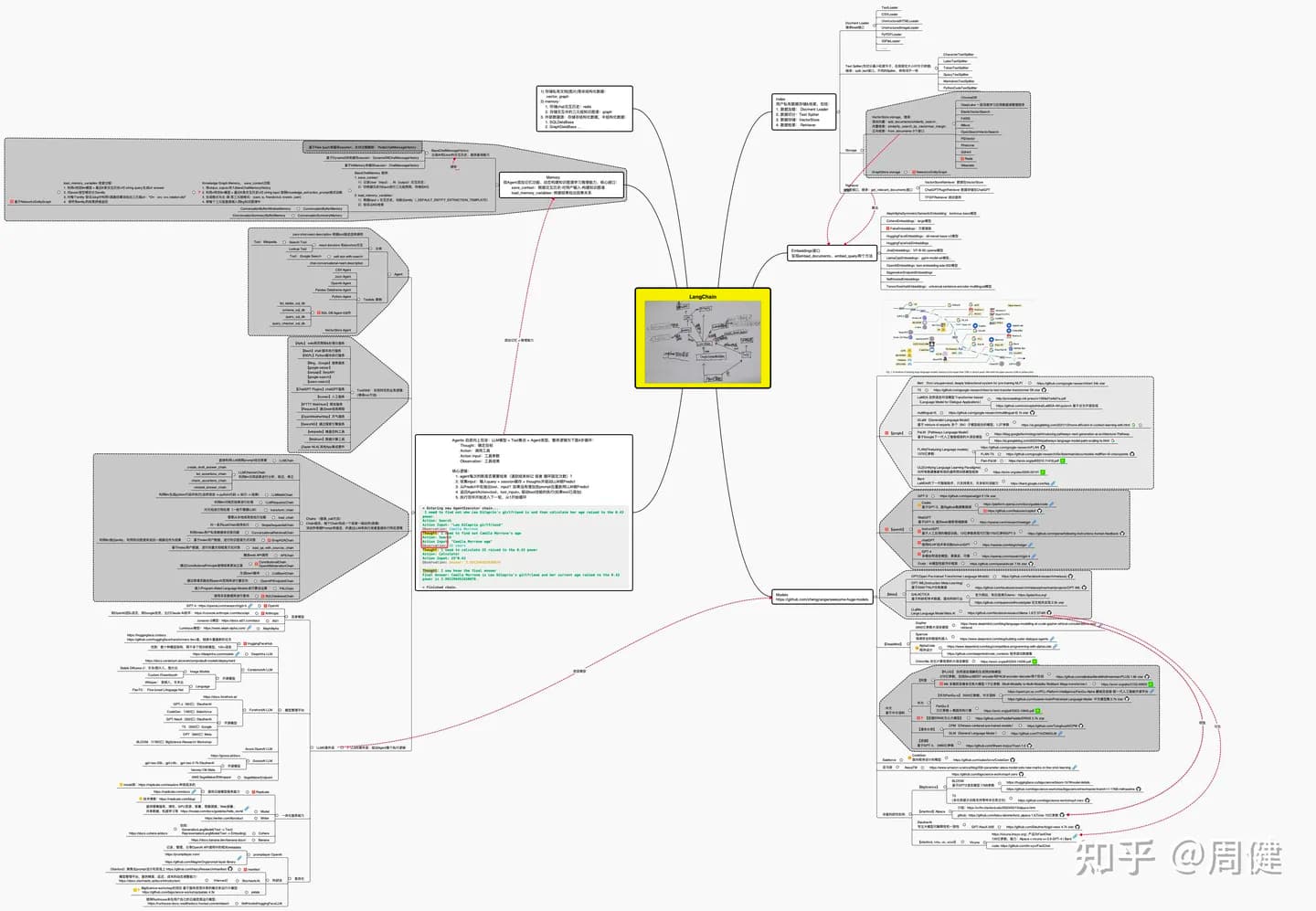
项目全景图
整体分为:基础层、能力层、应用层三部分(如果不清晰,建议点击github浏览)
{kind=link}
基础层
包括:Models、LLM、Index三层:
Models层:
吐血整理最近3年左右的模型、详细文档。可以看出各家大模型的演进历史,其中Google、OpenAI、Meta、DeepMind领先优势非常大,国内大厂唯独腾讯缺席。有几个点:
- 目前最主要的几个大模型为: Google的LaMDA、Meta的LLaMa、OpenAI的GPT-4、DeepMind的:Chinchilla
- 另外目前投入应用的智能终端基本都是基于模型的Fine-Tuning或者RLHF技术,并且需要大量的相关行业训练集,典型比如code领域、财经领域BloombergGPT、学术论文编写等,其中在作者最关注的Code细分领域,目前的模型有:
- OpenAI的Codex
- DeepMind的AlphaCode
- Saleforce的CodeGen
Models层的输出包括:
- 文本自动生成
- embeding向量化输出
- 多模态输出
LLMS层:
这一层主要强调对models层能力的封装以及服务化输出能力,主要有:
- 各类LLM模型管理平台:强调的模型的种类丰富度以及易用性
- 一体化服务能力产品:强调开箱即用
- 差异化能力:比如聚焦于Promp管理、基于共享资源的模型运行模式等等
Index层:
对用户私域文本、图片、PDF等各类文档进行存储和检索,这里有两个方案:
- Vector方案:即对文件先切分为Chunks,在按Chunks分别编码存储并检索
- KG方案:这部分利用LLM抽取文件中的三元组,将其存储为KG供后续检索
能力层
如果基础层提供了最核心的能力,能力层则给这些能力安装上手、脚、脑,让其具有记忆和触发万物的能力,包括:Chains、Memory、Tool三部分
Chains层:
按照不同的需求抽象并定制化不同的执行逻辑,Chain可以相互嵌套并串行执行,通过这一层,让LLM的能力链接到各行各业比如面向私域数据的load_qa_with_sources_chain; 比如面向SQL数据源的SQLDatabaseChain;再比如能自动生成代码并执行的LLMMathChain等等,这里面比较让人眼前一亮的点有:
- ConstitutionalChain:对最终结果进行偏见、合规问题处理的逻辑,保证最终的结果符合价值观
- LLMCheckerChain:能让LLM自动检测自己的输出是否有没有问题的逻辑
Memory层:
这层主要有两个核心点:
- 对Chains的执行过程中的输入、输出进行记忆并结构化存储,为下一步的交互提供上下文,这部分简单存储在Redis即可
- 根据交互历史构建知识图谱,根据关联信息给出准确结果
Tools层:
其实Chains层可以根据LLM + Prompt执行一些特定的逻辑,但是如果要用Chain实现所有的逻辑不现实,可以通过Tools层也可以实现,Tools层理解为技能比较合理。典型的比如搜索、维基百科、天气预报、chatGPT服务等等。
应用层
有了基础层和能力层,我们可以构建各种各样好玩的,有价值的服务,这里就是Agent
Agent层:
Agent层可以根据Tool和Chain组合出特定的服务来,最终实现以更自然的文本交互形态完成用户特定需求的目标,比如用自然语言的方式实现sql的操作等等。
from:LangChain全景图 - 知乎