在进行总结的时候,经常会输出英文,请问有没有办法只让输出中文呢?
1 个赞
目前并没有一种直接的方式来限制模型只输出特定的语言。这是因为这些模型在训练时是以多语言的方式进行的,这意味着它们可以理解和生成多种语言的文本,包括英语和中文。模型的输出会基于输入的内容以及模型对于任务的理解,所以如果你在使用中文与模型交互,那么模型的输出通常会是中文。
如果你希望模型尽可能地只输出中文,你可以尝试以下的策略:
- 确保你的输入完全是中文。模型会根据输入的语言来决定它的输出,所以如果你只输入中文,模型就更有可能只输出中文。
- 在你的输入中明确指出你希望模型只使用中文。例如,你可以在你的问题或指令中添加一句prompt“请只用中文回答”。
- 如果可能,尝试避免使用在英文中更常见的主题或术语。这可能有助于减少模型生成英文输出的可能性。
1 个赞
文章总结还能指定prompt吗
你的使用方式可以发出来看下,绝大多数情况下,都可以定制system prompt的
from langchain import OpenAI, PromptTemplate, LLMChain
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains.mapreduce import MapReduceChain
from langchain.prompts import PromptTemplate
from langchain.docstore.document import Document
from langchain.chains.summarize import load_summarize_chain
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = CharacterTextSplitter()
loader = UnstructuredFileLoader("/www/wwwroot/gpt.admin.io/public/quque/data/20230612143246198_summarize.txt")
# 将文本转成 Document 对象
document = loader.load()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 100,
chunk_overlap = 10,
)
print(f'documents:{len(document)}')
# 切分文本
split_documents = text_splitter.split_documents(document)
print(f'documents:{len(split_documents)}')
llm = OpenAI(openai_api_key="",model_name="text-curie-001",max_tokens=1024,temperature=0.3)
prompt_template = """Write a concise summary of the following:
{text}
使用中文回复:"""
PROMPT = PromptTemplate(template=prompt_template, input_variables=["text"])
# chain.run(docs)
chain = load_summarize_chain(llm, chain_type="refine", question_prompt=PROMPT)
result = chain.run(split_documents[:len(split_documents)])
以上为我的实现代码

把“Write a concise summary of the following”替换为“请根据下面的内容做一下总结(注意:请使用中文回复)”试一下?
感谢大佬,我尝试一下
经过尝试依然是这样:The Daoist dynasty of the Xia Dynasty was ruled by the Great State of Zhao. Outside of the city of Zhao, the mountains were steep and the forests dense, giving the state plenty of hiding places. However, there were also powerful warriors from other states, as well as bandits who thrived in the lawless environment. The state had to rely on its strong military to keep these threats at bay. The state’s nine provinces were connected by four roads, making it easy for trade to flow in and out. The state had a large number of wealthy merchants living within its walls. The state was surrounded by mountains, but the south was dominated by the mountains.
以下为文章内容:
大乾王朝。严州城外,奇山陡峭,山林坐落,巍峨入云。山林之中坐落的大小寨院络绎不绝。此刻。黑风寨当中。主屋的门外站着个穿粗布衣的汉子,头发草草拢起来,略腮胡长了半脸,粗着嗓子叫道:“少当家的!二当家的等着您去忠义堂商量事呢!”嗓子像是把破锣,房内的萧山就是想假装没听见也不行了。从床上做起来,海量般的记忆鱼贯而入。萧山消化了全部的记忆信息。默默的叹了口气,自己这是刚穿越就死了便宜老爹啊。自己现在是大乾王朝,严州城外黑风寨的少当家。大乾王朝不是自己在历史传记里看到的任何一个王朝。而是一个完全架空的古代王朝。大乾之广,疆域辽阔,其中名门山庄,各宗各派不在其数!其中实力超群的强大武者更是数不胜数,武道高手飞天遁地以一敌万,绝不仅仅存在于传说之中。而除了那些武林之中的名门正派之外。还有与之立场截然相反的魔教鼎立。如此一来,其中还有江湖流匪,闲散之人踽踽独行,也有人拉帮结伙,自立门派,成了大乾王朝武林之中不可忽略的一笔。严州城为大乾王朝的九州通衢,交通便利四通八达,无数富商居于城中,紧邻大乾都城,南邻山峰不绝。正是这个原因,无数流匪团伙在严州城外的险山之中扎地为营。黑风寨就是其中一个。而萧山死了不久的便宜老爹,便是黑风寨的上一任大当家。
1 个赞
感觉最终送到ChatGPT的内容不是你期望的输入,你加一下StdOutCallbackHandler看一下,调用时候的具体调用参数看一下
这个参数加哪里呢?请问有相关文档吗?谢谢
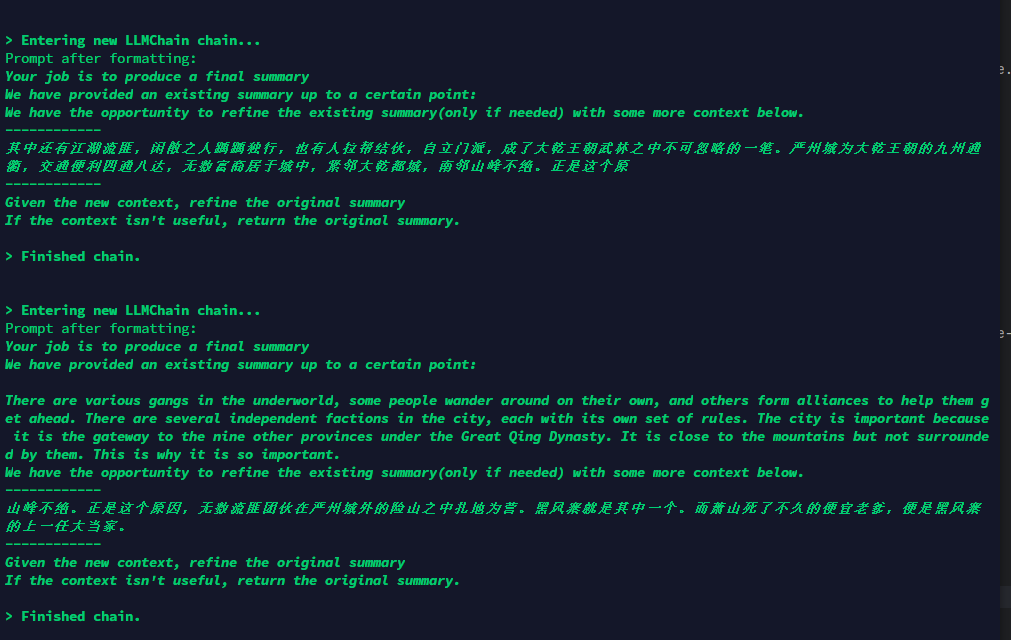

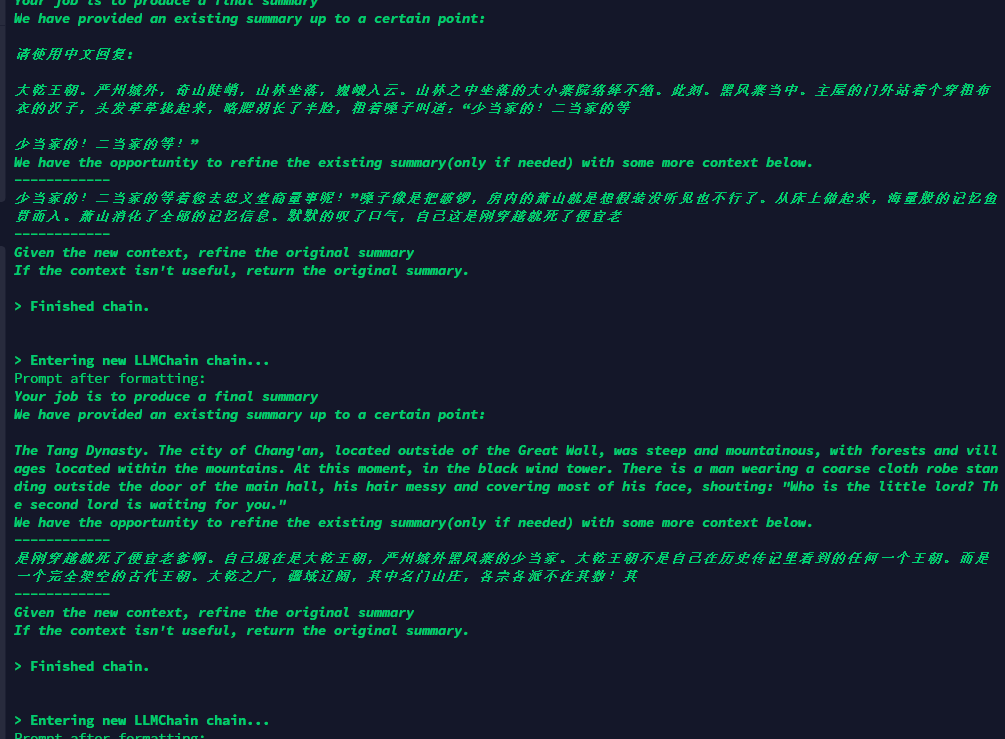
也遇到了一样的问题,待总结的数据是中文的,用了load_summarize_chain后,总结完成后的内容全是英文。

load_summarize_chain自动使用的prompt信息通过什么样的方式可以直接把这些内容设置成中文的?
prompt_template = """对下面的文字做精简的摘要:
{text}
"""
PROMPT = PromptTemplate(template=prompt_template, input_variables=["text"])
chain = load_summarize_chain(llm, chain_type="map_reduce", return_intermediate_steps=True, map_prompt=PROMPT, combine_prompt=PROMPT)
summ = chain({"input_documents": docs}, return_only_outputs=True)
麻烦问下相关问题解决了吗?怎么解决的呀?