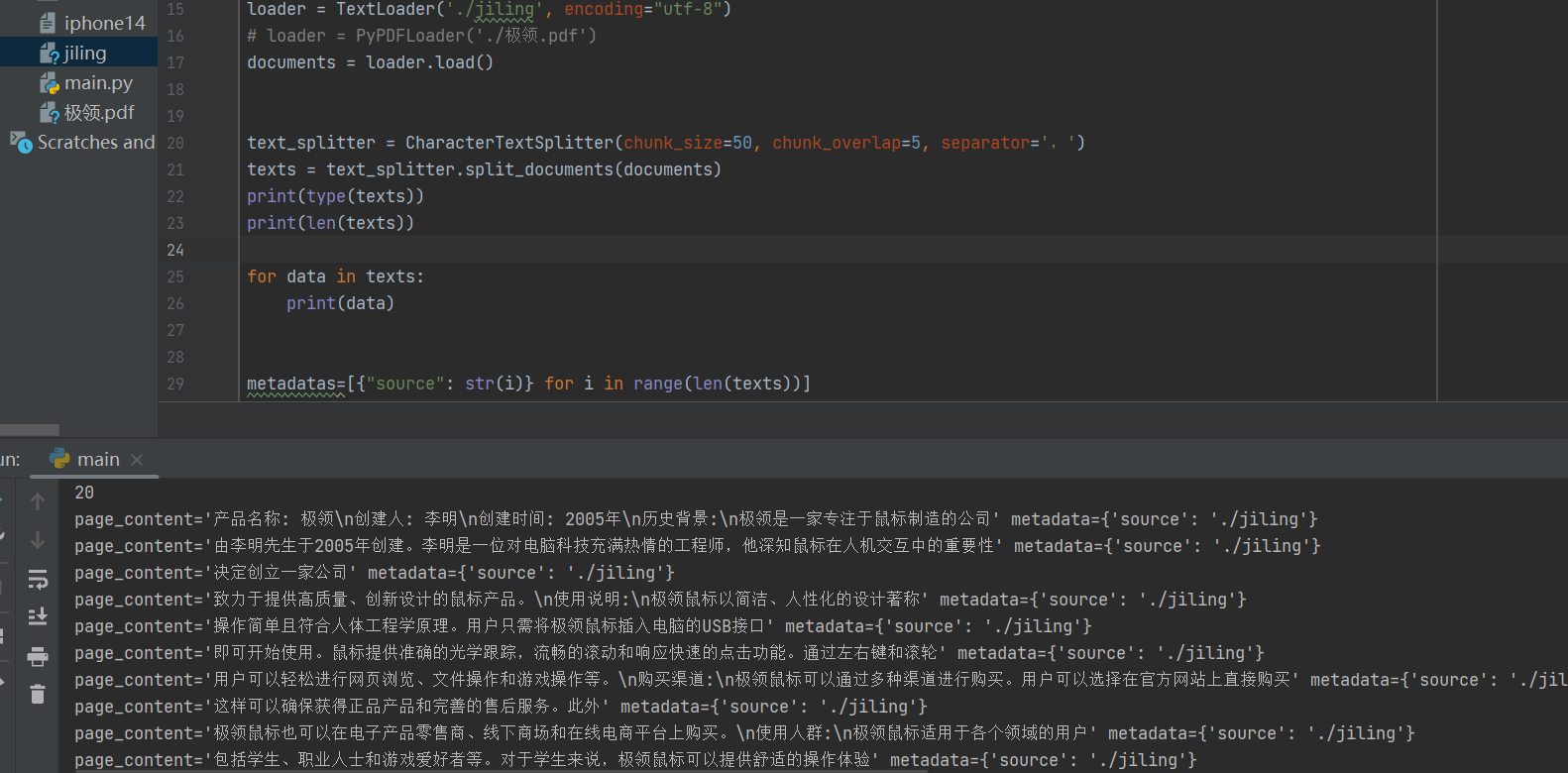
按照chunk_size = 50 , chunk_overlap=5, separator=','对文本进行切割,为什么切割出来的document,长的长短的短, 还有些document里面包含有逗号。这个切割的逻辑到底是啥?
文本切割是将长篇文本拆分成较小的语义上有意义的块的过程。切割的逻辑是:
- 首先,将文本按照特定的方式分割成较小的块,通常是句子。
- 然后,开始将这些小块组合成一个较大的块,直到达到一定的大小,由某些函数来测量大小。
- 一旦达到块的大小限制,该块被视为一个完整的文本块,并开始创建一个新的块,与上一个块有一定的重叠(以保持文本块之间的上下文)。
根据切割器的不同,文本可以根据特定的标记进行切割,例如Markdown标题、代码块或水平线。
关于切割结果的理解,可以通过查看切割后的文本块或使用适当的工具来处理和分析它们。每个文本块代表一个语义上相关的部分,您可以根据需要进一步处理、分析或操作这些文本块。
求问chunk_size的具体意义指的是什么?是一个字符还是别的什么意思?
就是切割出来的文本的最大长度!
举一个具体的例子来说明吧。我是这么理解chunk_size和separator的关系的:
以如下文本为例,以chunk_size = 8,separator = ‘,’为参数:
[“阿斯顿发阿萨德,大沙发靠阿道夫,达到,而且,发觉我二,切尔奇奇情况, 安三胖放进去为大发放安抚, 阿阿道夫,爱欧吃矛,五六千”]
1、将文本以逗号进行分割。
2、如果分割之后的文本长度小于8,则可以进行合并,比如“达到”,“而且”,“发觉我二”,单个文本的长度小于8,合并之后也不大于8,所以会将这三个合并到一起当做一个文本。
3、如果分割之后的文本长度大于8,比如"安三胖放进去为大发放安抚",这种大于8的长度的文本因为无法按照逗号分割,所以也只能保留下来作为一个文本。但是这种情况在后面操作的时候好像会报错,所以在设计chunk_size的时候,还是要注意一些。
如果不设置separator,单纯地分割一个txt文本。
比如说:
今天天气很好,明天天气也很好,后天天气也很好。
如果chunk_size=5,
分割后是不是就是:
今天天气很
好,明天天
气也很好,
后天天气也
很好
不会出现超过5的情况?
chunk_size设置得很大吗?还是比分割后的文本小很多?
没明白你什么意思!
就是你刚才的例子中,说是几乎把整个文章当做了一个文本,这里面的chunk_size设置的是多少?然后文章有多少字大概?
不大,就设置了chunk_size=50,然后使用默认的seperator=‘\n\n’,整个文章就没有分隔开,整篇文章作为了一个文本。 ![]()
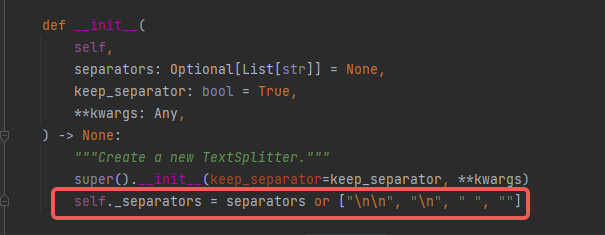
默认的分割符号就是这4种。如果是英文的话,估计不会出现整个文章没有分隔开的情况。因为两个英文单词一般至少存在一个空格把这两个单词分开。
但是中文的话,现在看来还是需要整理一下原文件的格式,然后指定分隔符这样比较好。
你说的这个是RecursiveCharacterTextSplitter默认是[“\n\n”, “\n”, " ", “”]
CharacterTextSplitter默认的只有’\n\n’