向量数据库和嵌入是当前人工智能领域的热门话题。向量数据库公司Pinecone刚刚以约10亿美元的估值筹集了1亿美元。Shopify、Brex、Hubspot和其他公司在其人工智能应用程序中使用它们。但它们是什么,它们如何工作,为什么它们在人工智能中如此关键?让我们来了解一下
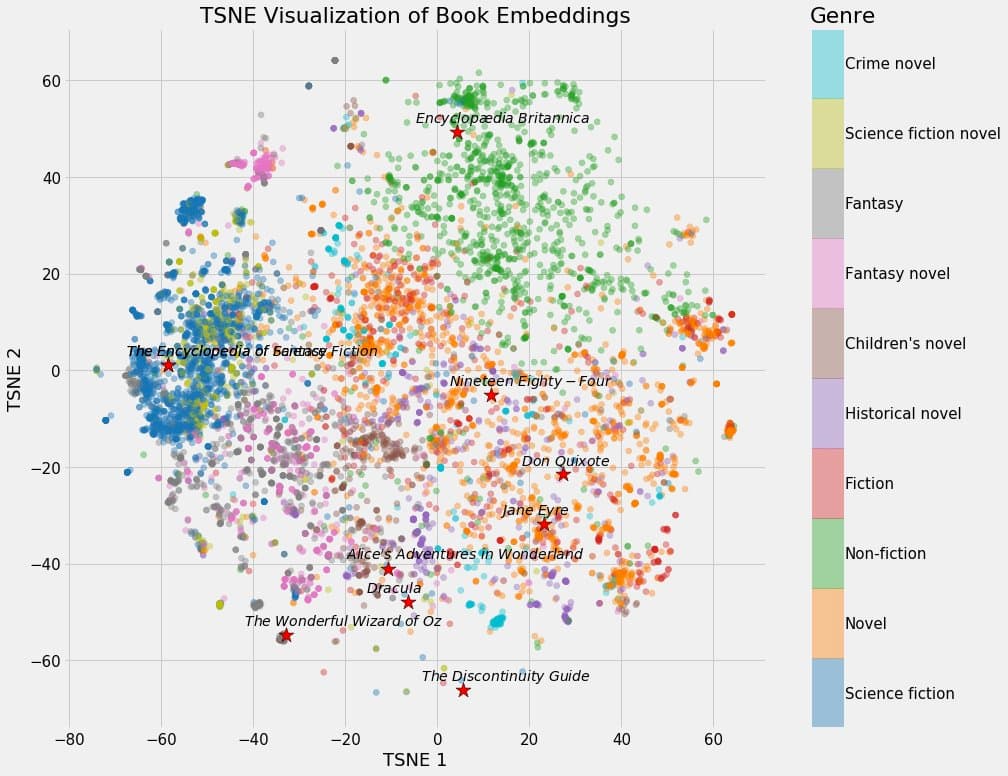
首先,什么是向量嵌入?你可能已经在微博上看到这个词被抛出了无数次了
简单的解释是:
嵌入只是一个N维的数字向量。它们可以代表任何东西,文本、音乐、视频等等,我们将专注于文本。
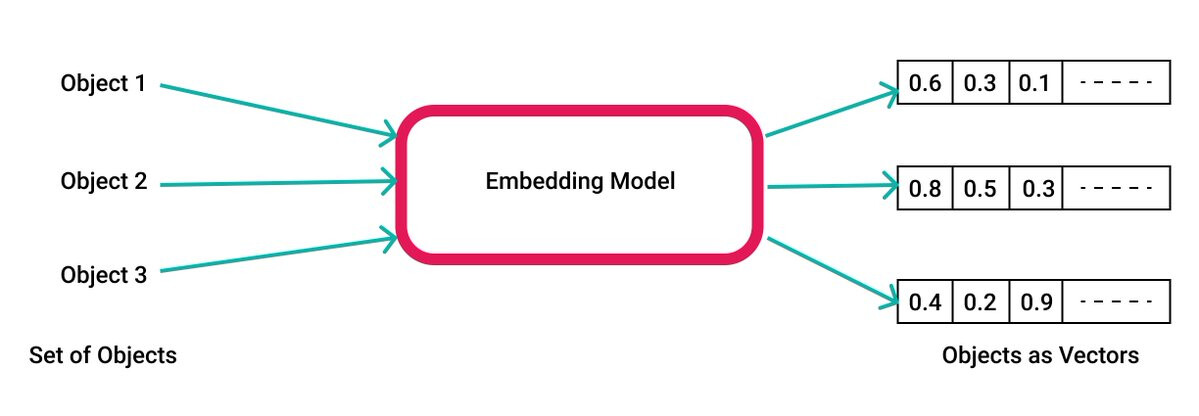
创建一个嵌入的过程是直接的。它涉及一个嵌入模型(例如:Openai的Ada)。
你把你的文本发送给模型,它为你创建一个数据的向量表示,它可以被存储并在以后使用。
它们很重要,因为它们给了我们语义搜索的力量,这只是意味着通过相似性进行搜索。比如通过文本的含义。
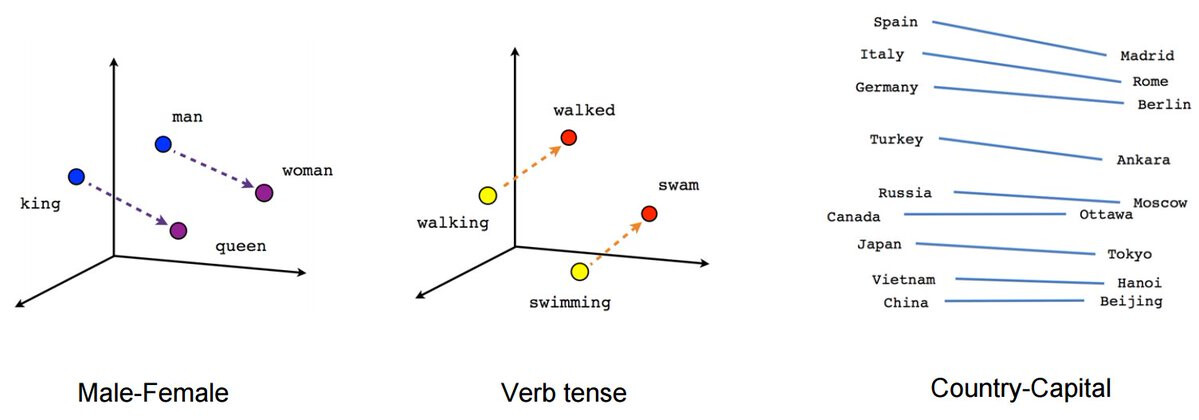
因此,在这个例子中,我们可以在一个矢量平面上建立一个男人、国王、女人和女王的模型,并非常容易地看到他们之间的关系。
这里有一个稍微直接一点的例子:
想象一下,你是一个有一大箱玩具的孩子。现在你想找一些有点相同的玩具,比如玩具车和玩具巴士。
它们都是车辆,所以它们是相似的。
这被称为 “语义相似性”。- 当事物具有类似的意义/想法时。
现在让我们说说你有两个相关的玩具,但并不一样。比如一辆玩具车和一条玩具路。
它们不一样,但确实属于一起,因为汽车通常在路上行驶。
在一个理想的世界里,我们可以在LLM的提示中容纳无限多的词语。
但正如你们中的许多人所知,我们做不到。现在,它被限制在~4096 - 32k tokens。
因此,由于LLM的 “内存”,也就是我们能在其令牌限制中容纳多少字,我们与LLM的互动方式受到了严重限制。
这就是为什么你不能把PDF复制粘贴到chatGPT中并要求它进行总结。(也许你现在可以,因为gpt4-32k)。
现在,这一切是如何最终拼凑起来的呢?
我们可以利用矢量嵌入的优势,将相关文本注入LLM的上下文窗口。
让我们来看看一个例子:
说你有一个巨大的PDF,也许是一个国会听证会的PDF(呵呵)
你很懒,所以你不想读完整个文件,而且你不能粘贴整个文件,因为它有10亿页长。
这就是嵌入的完美用例。
因此,你把PDF,并创建一个矢量嵌入,并将其存储在数据库中。
现在你问一个问题,“他们对xyz说了什么”
我们首先:创建一个你的问题的嵌入:“他们对xyz是怎么说的”
现在我们有两个向量:你的问题[1,2,3]和PDF[1,2,3,34] 。
然后我们用相似性搜索来比较问题向量和我们的巨型PDF向量。openai推荐的是余弦相似度。
好了,现在我们有了:
3个最相关的嵌入物和文本
我们现在可以使用这3个嵌入物的输出,并通过一点提示工程将其送入LLM。
最常见的是:
根据上下文,如实回答用户的问题。
如果你不能回答,那么就说 “我不能回答这个问题”,就可以了!
LLM从你的PDF中获取相关的文本块,并试图如实回答你的问题。
这是关于嵌入和LLMs如何为任何形式的数据提供相当疯狂的聊天能力的超级基本解释。
这也是所有那些 "与你的网站/pdf/blah blah聊天 "的工作原理!
from:https://twitter.com/SullyOmarr/status/1655626095717232664