Python版本
环境:

代码如下:
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter, CharacterTextSplitter
import faiss
from langchain_community.vectorstores import FAISS
def build_vector_db():
"""构建向量数据库"""
loader = TextLoader('../documents/santi.txt')
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20
)
split_docs = text_splitter .split_documents(docs)
print("Type of split_docs:", type(split_docs))
# texts = [doc.page_content for doc in split_docs]
print(split_docs)
# vector_db = FAISS.from_texts(texts, embeddings)
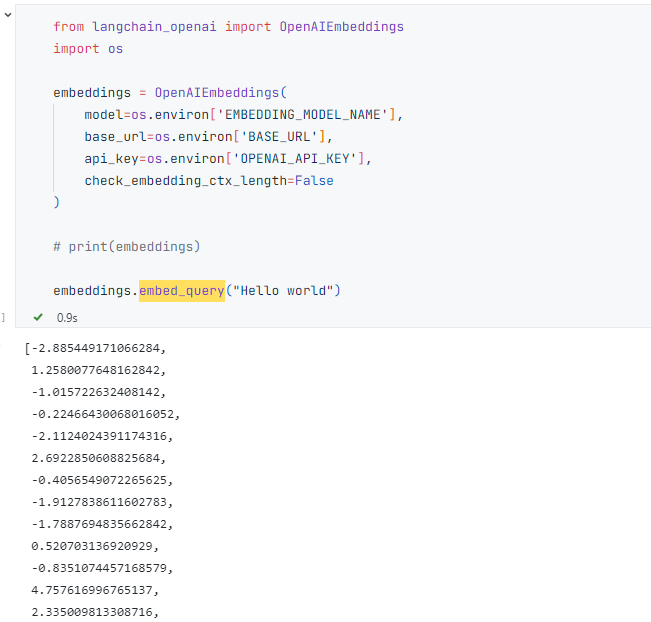
embedding = OpenAIEmbeddings(
model="text-embedding-v1",
base_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
api_key='sk-xxxxxxxx',
)
vector_db = FAISS.from_documents(documents=split_docs, embedding=embedding)
# vector_db = FAISS.from_texts(texts=texts, embedding=embedding)
# vector_db.save_local('../db/sport_db')
build_vector_db()
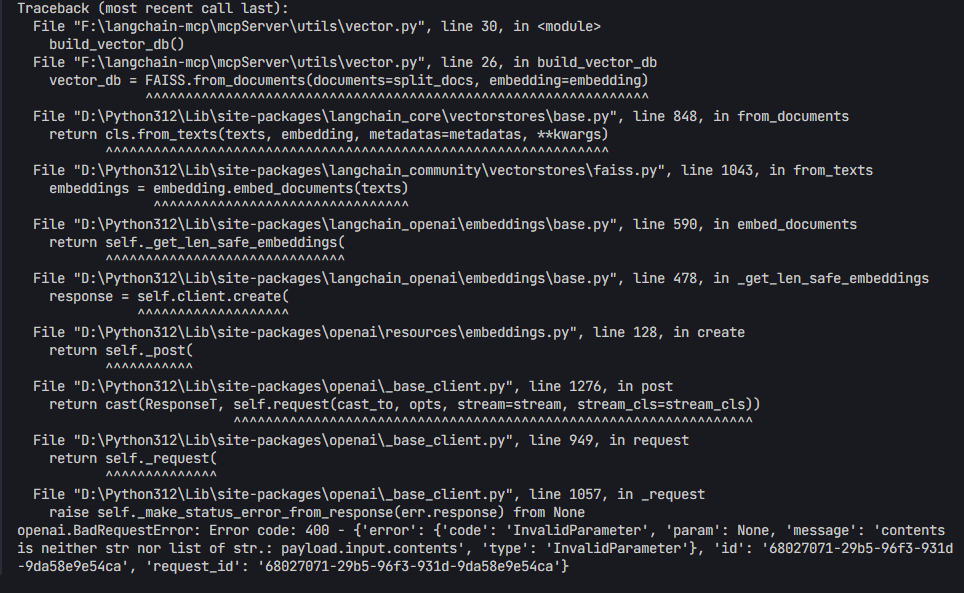
执行到 FAISS.from_documents 这一步就会报错![]() ,错误信息如下:
,错误信息如下:
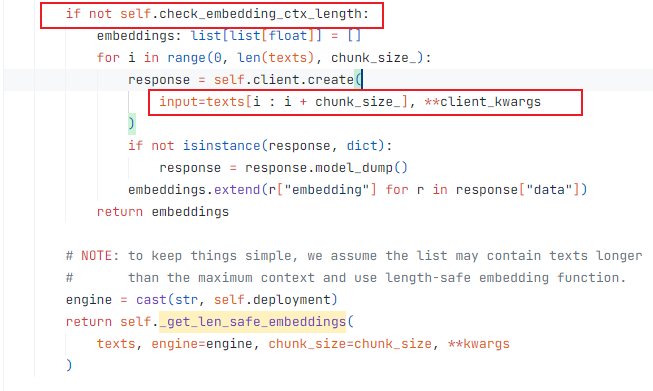
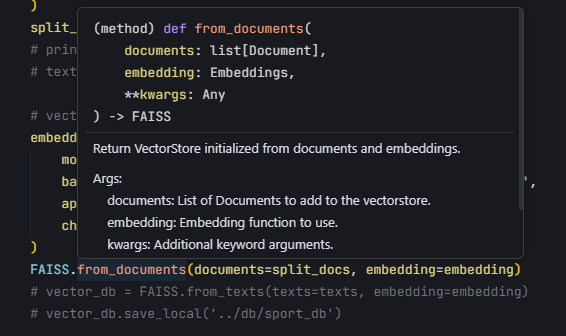
参数类型没看出有什么问题,这是官方文档要求的参数类型:
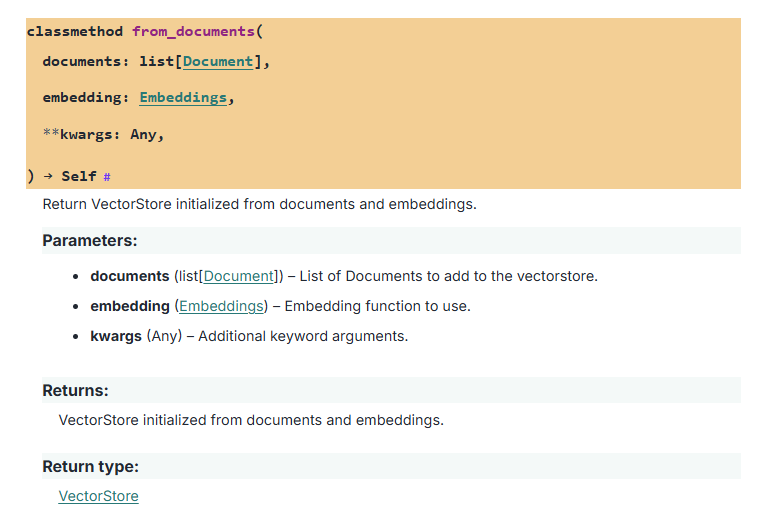
这是代码里的参数类型:

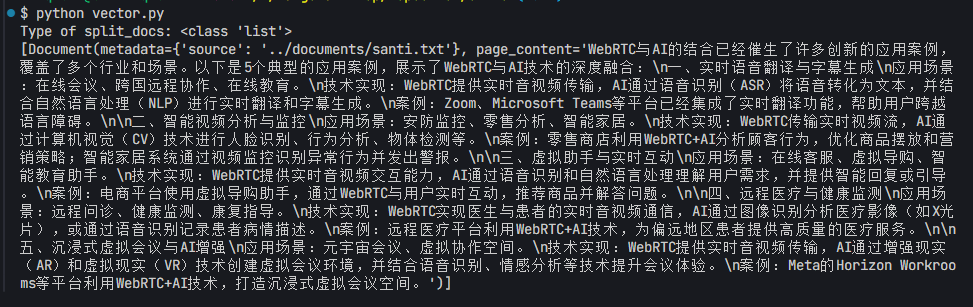
split_docs 也能够正常打印出来:
版本号:
![]()
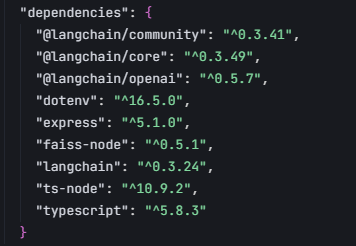
JS版本
环境:
![]()
同样的api,同样的txt文件,包括向量模型都是用的同一个,在js版本中却是正常的:
import { TextLoader } from "langchain/document_loaders/fs/text";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import "dotenv/config";
import { FaissStore } from "@langchain/community/vectorstores/faiss";
import { OpenAIEmbeddings } from "@langchain/openai";
const run = async () => {
const loader = new TextLoader("../documents/data.txt");
const docs = await loader.load();
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 100,
chunkOverlap: 20,
});
const splitDocs = await splitter.splitDocuments(docs);
const embeddings = new OpenAIEmbeddings({
model: process.env.EMBEDDING_MODEL_NAME,
configuration: {
baseURL: process.env.BASE_URL,
apiKey: process.env.OPENAI_API_KEY,
},
});
const vectorStore = await FaissStore.fromDocuments(splitDocs, embeddings);
const directory = "../db/news";
await vectorStore.save(directory);
};
run();
运行结果也生成了文件:
版本号:
希望有大佬指导一下,Python版本到底问题出在哪里,已经卡了我半天了,问了DeepSeek,给的结果也试了,都不行。感谢!感谢!
--------------------------------------------------------------------分割线------------------------------------------------------------
问题解决了!!!
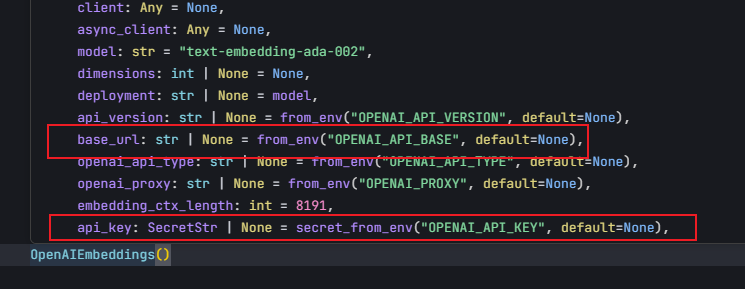
问题并不在 FAISS.from_documents,而是在前面创建 embeddings就有问题。因为我用的是阿里云的向量模型,JS版本可以直接用OpenAIEmbeddings指定baseURL来接入其他厂商的模型,我是先写的js,后面写python的时候,就很自然的以为python也是一样的操作,关键是OpenAIEmbeddings的入参类型提示里也有这两个参数:
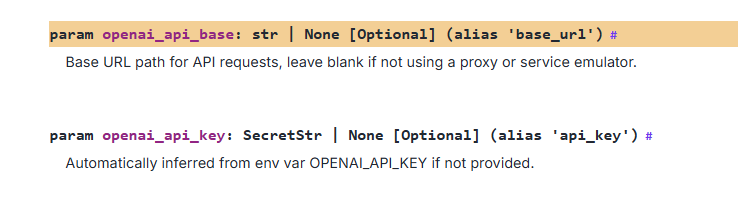
看了官方文档,又发现好像没有这两个参数,只有下面这两个,试了也不行
最后解决方案就是直接用
community包里的DashScopeEmbeddings,这个是特供阿里云的
embedding = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key='sk-xxxxxxxx',
)
其实还是很疑惑为啥两个版本有这样的差异,但是现这样吧,能解决就好,如果有大佬知道OpenAIEmbeddings能不能跟JS版本一样通过其他的配置参数来接入不同厂商,希望能留个言。
完结撒花!!!