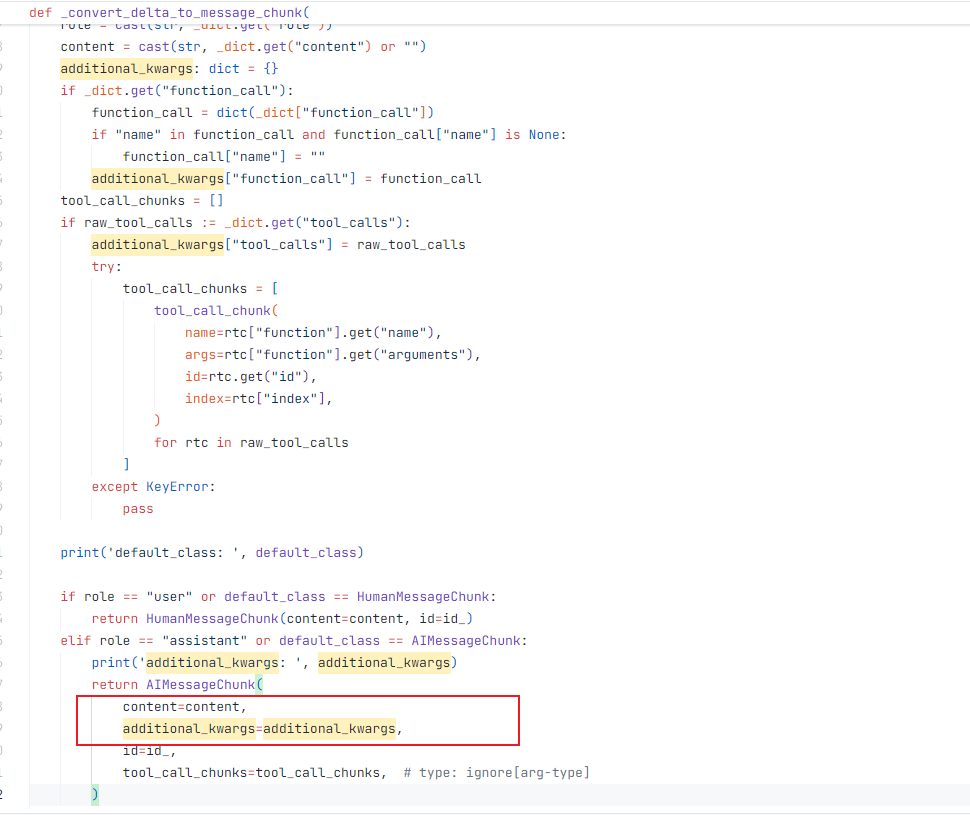
代码如下:
from langchain_openai import ChatOpenAI
import os
chat_model = ChatOpenAI(
model=os.environ["MODEL_NAME"],
temperature=0.5,
base_url=os.environ["BASE_URL"],
api_key=os.environ["OPENAI_API_KEY"],
extra_body={
"enable_thinking": True,
"return_reasoning": True,
},
streaming=True,
)
for chunk in chat_model.stream("你好, 请介绍一下你自己"):
print(chunk)
运行结果:
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='你好!' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='我是Qwen3' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content=',是阿里巴巴集团' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='旗下的通义实验室' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='自主研发的超大规模' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='语言模型。我可以' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='帮助你回答问题' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='、创作文字、' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='编程、表达观点' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='等。如果你有任何' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='问题或需要帮助' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content=',欢迎随时告诉我' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='!' additional_kwargs={} response_metadata={} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
content='' additional_kwargs={} response_metadata={'finish_reason': 'stop', 'model_name': 'qwen3-235b-a22b'} id='run--af26814e-2c74-474d-8b2c-ac84a9b30026'
可以看到,前面的思考过程,除了id,什么信息都没有输出。
而如果使用ChatTongyi,则是正常的,代码如下:
from langchain_community.chat_models.tongyi import ChatTongyi
import os
chat_model = ChatTongyi(
model=os.environ["MODEL_NAME"],
api_key=os.environ["OPENAI_API_KEY"],
streaming=True
)
is_thinking = False
for chunk in chat_model.stream("你好, 请介绍一下你自己"):
if chunk.content:
if is_thinking:
print('\n\n' + '='*200 + '\n')
is_thinking = False
print(chunk.content, end="", flush=True)
elif chunk.additional_kwargs['reasoning_content']:
if not is_thinking:
print('思考过程:' + '\n')
is_thinking = True
print(chunk.additional_kwargs['reasoning_content'], end="", flush=True)
运行结果如下:
思考过程:
嗯,用户让我介绍一下自己。首先,我需要确定用户的需求是什么。他们可能想了解我的功能、开发背景,或者应用场景。作为通义千问,我应该涵盖几个关键点:我的研发机构(通义实验室),我的能力范围(回答问题、创作文字、编程等),以及我的多语言支持。
然后,我需要考虑用户的潜在需求。他们可能不仅想知道我的基本功能,还可能关心我与其他模型的区别,比如超大规模参数量、训练数据量以及推理能力。此外,用户可能对实际应用感兴趣,比如写故事、写公文、写邮件等具体场景。
还要注意用户可能的疑问,比如我的训练数据截止时间,是否支持多语言,以及如何保持回答的准确性和时效性。需要明确说明数据截止到2024年10月,并强调持续更新和优化。
另外,用户可能希望了解我的安全性和可靠性,所以在回答中可以隐含这些信息,比如提到经过严格测试和优化,确保输出内容的安全性和准确性。最后,保持语气友好,邀请用户进一步提问,促进互动。
========================================================================================================================================================================================================
你好!我是通义千问,由通义实验室研发的超大规模语言模型。我可以帮助你:
1. **回答问题**:无论是学术问题、常识问题还是专业领域问题,我都可以尝试为你解答。
2. **创作文字**:写故事、写公文、写邮件、写剧本等,我都可以帮你完成。
3. **逻辑推理**:我可以帮助你进行逻辑推理和解决问题。
4. **编程**:我可以理解并生成多种编程语言的代码。
5. **多语言支持**:除了中文,我还支持英文、德语、法语、西班牙语等百种语言。
我的训练数据截止到2024年10月,这意味着我对这一时间点之前的信息有较好的了解。如果你有任何具体问题或需要帮助,欢迎随时告诉我!
也就是在additional_kwargs里面会包含有思考过程的内容。
想请教一下,就是ChatOpenAI 是不支持吗?那如果其他厂商的模型呢?每个厂商都要单独导一个包去写感觉很麻烦,也需要花时间去一一验证是否支持。
有没有其他的方案,有大佬懂的请留言,谢谢![]()