1. 基于KG知识图谱的知识引擎
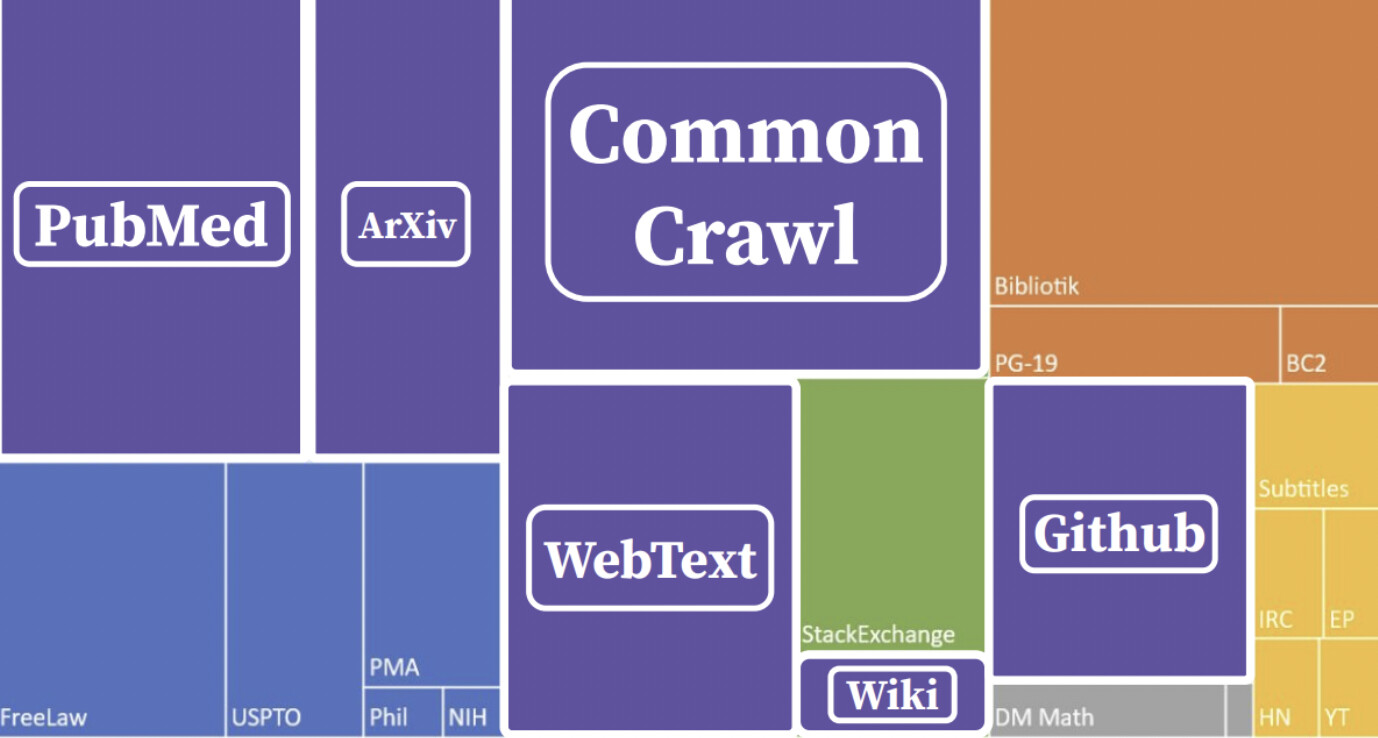
2. 基于LM预训练语言模型的知识引擎
语言模型是根据已知文本生成未知文本的模型。自GPT-3以来,大型语言模型展现出了惊人的zero-shot和few-shot能力,即不改变参数仅改变输入的in-context learning。这是与此前流行的finetune范式截然不同的新范式。近期的ChatGPT,更是让文本生成从以前人们眼中的玩具,逐渐展现出了生产力工具的潜质。本系列文章会介绍大型语言模型相关的重要论文,以期与更多的人一起熟悉这一新的范式。
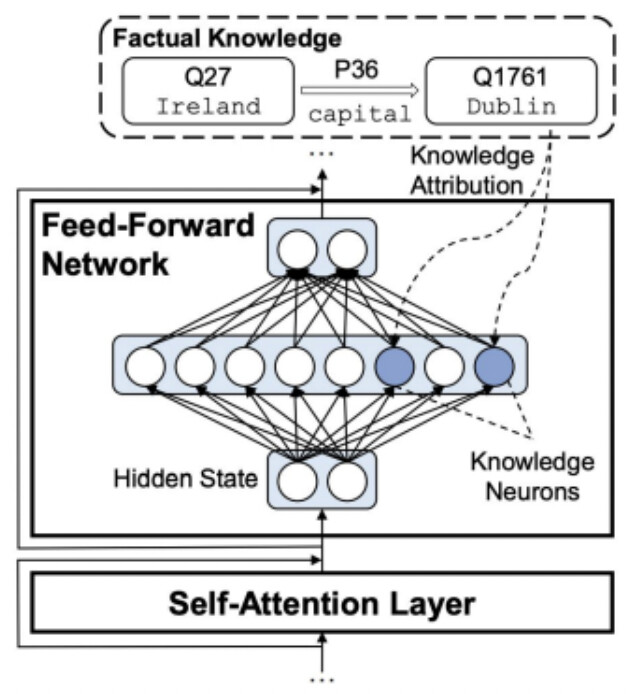
Transformer Feed-Forward Layers Are Key-Value Memories和Knowledge Neurons in Pretrained Transformers。大型语言模型的强大能力离不开其对知识的记忆:比如模型想要回答“中国的首都是哪座城市?”,就必须在某种意义上记住“中国的首都是北京”。Transformer并没有外接显式的数据库,记忆只能隐式地表达在参数当中。本期的两篇文章指出,与attention相比不那么引人注意的FFN承担了transformer中记忆的功能。
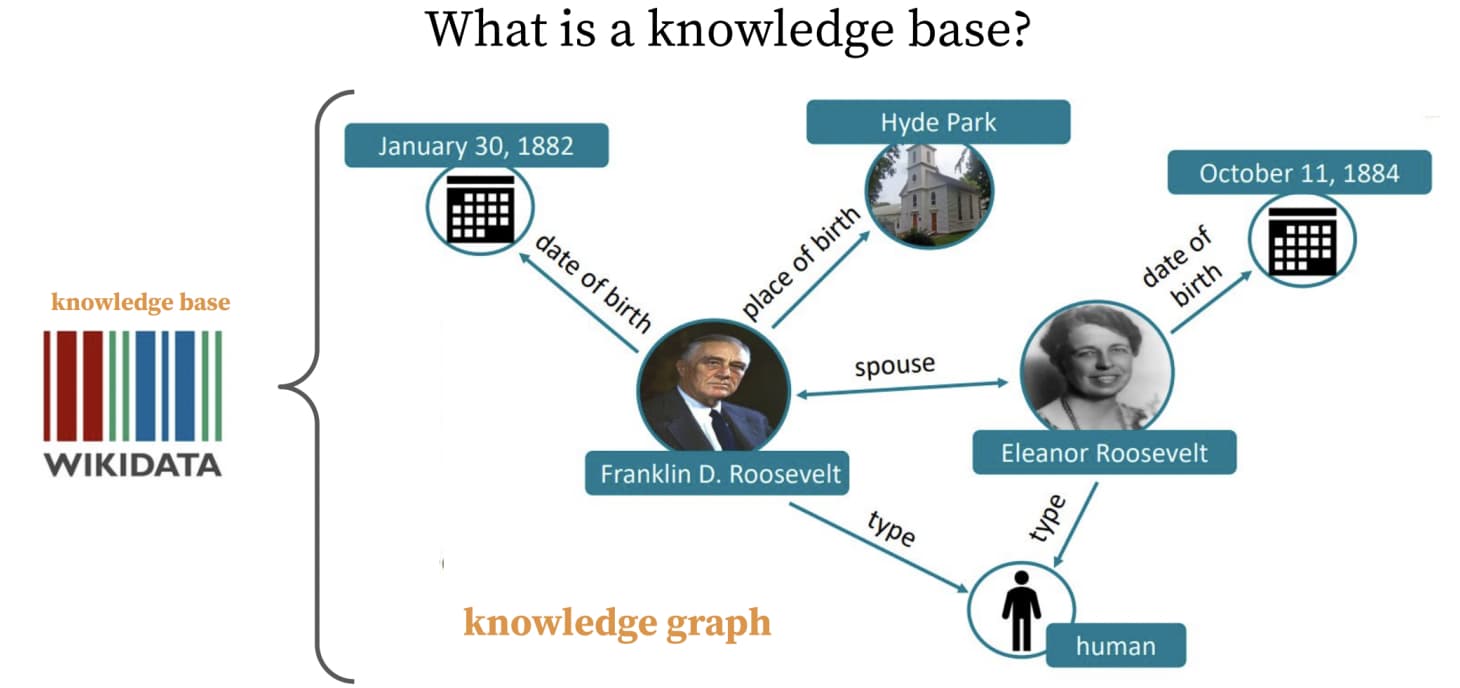
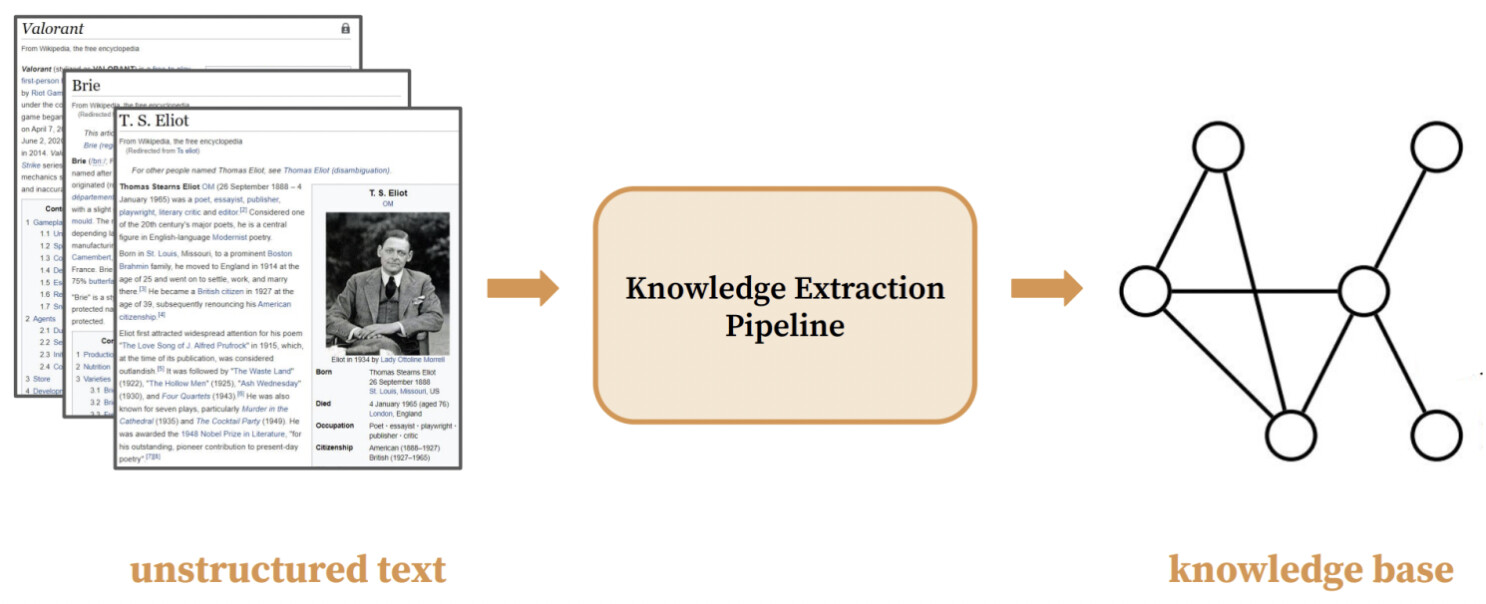
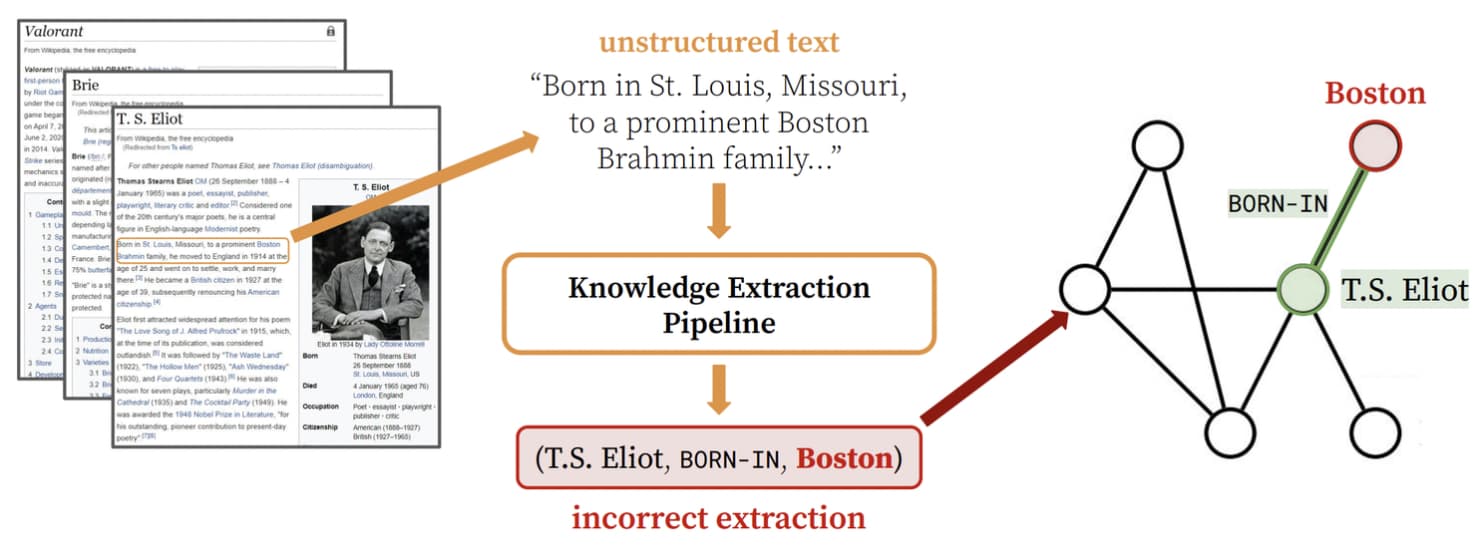
知识的定义:
知识的存储:
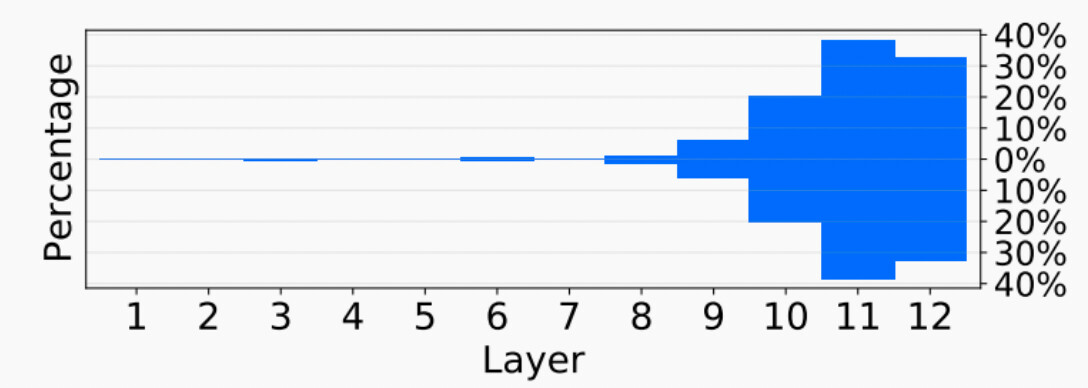
对于知识神经元的统计发现,大部分知识神经元都在transformer模型的最上层
在神经网络中添加记忆模块并不是一个新的想法。早在2015年的End-To-End Memory Networks中,就提出了key-value memory的结构
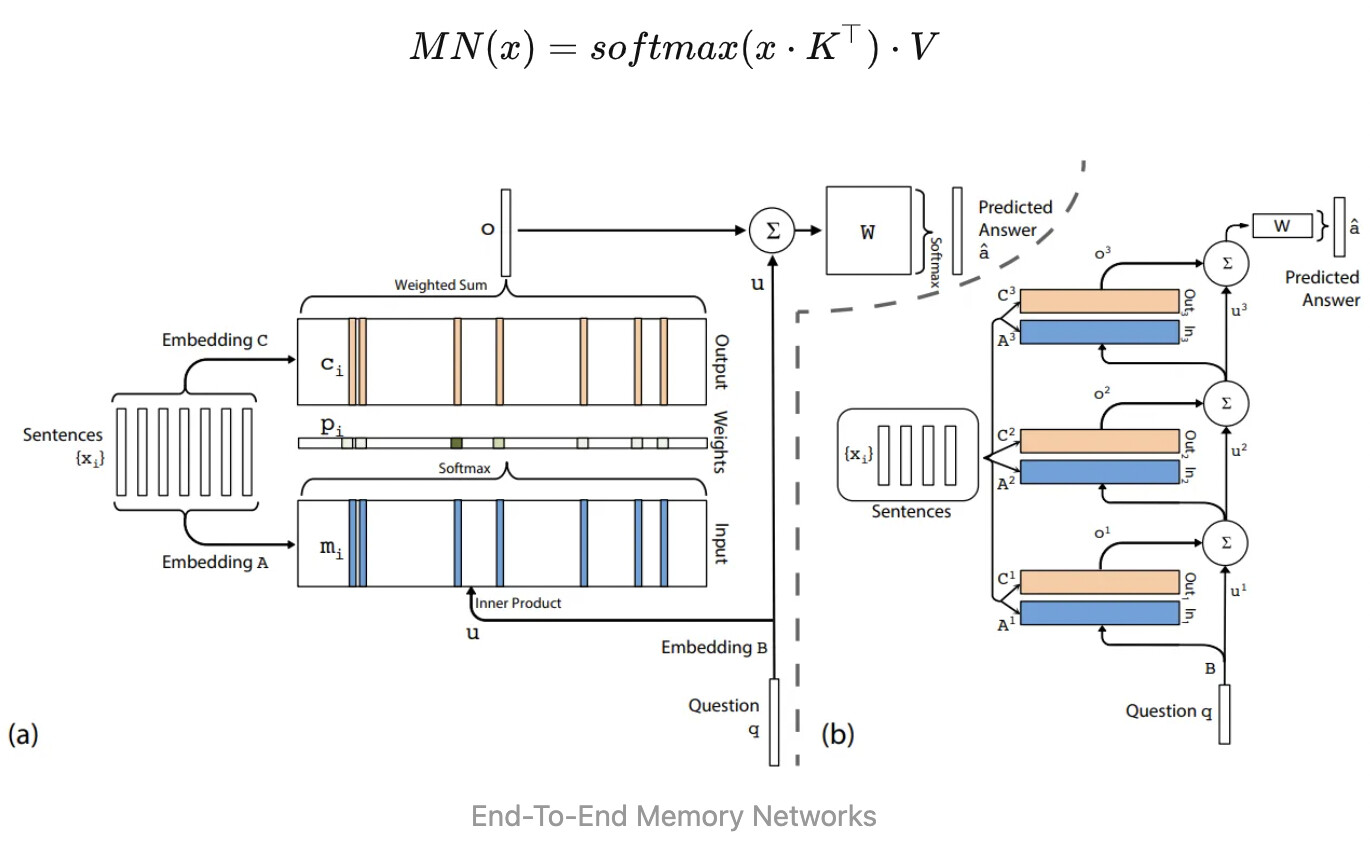
可以看出,FFN几乎与key-value memory相同。第一层权重对应key矩阵,第二层权重对应value矩阵,中间层维度对应memory token数量(或许是中间层维度需要较大的一种解释)。唯一的区别在于FFN的激活函数并不要求归一化。
Knowledge Neurons in Pretrained Transformers提出了一种关系类事实对应的FFN中间神经元的方法。其构造补全关系类事实的填空任务,用答案关于FFN中间神经元的梯度来确定存储知识的神经元,梯度大意味着该神经元对输出答案的影响大。实验中,平均每个关系类事实对应4.13个知识神经元,同种关系的不同事实平均共享1.23个知识神经元,而不同关系几乎不共享知识神经元。。
定位知识神经元以后就可以对相关神经元进行操作。如下图所示,将知识神经元的激活置0或翻倍可以有效抑制或增强相关知识的表达。在具体操作上,应避开同种关系共用的神经元,以减小对其他事实的影响。
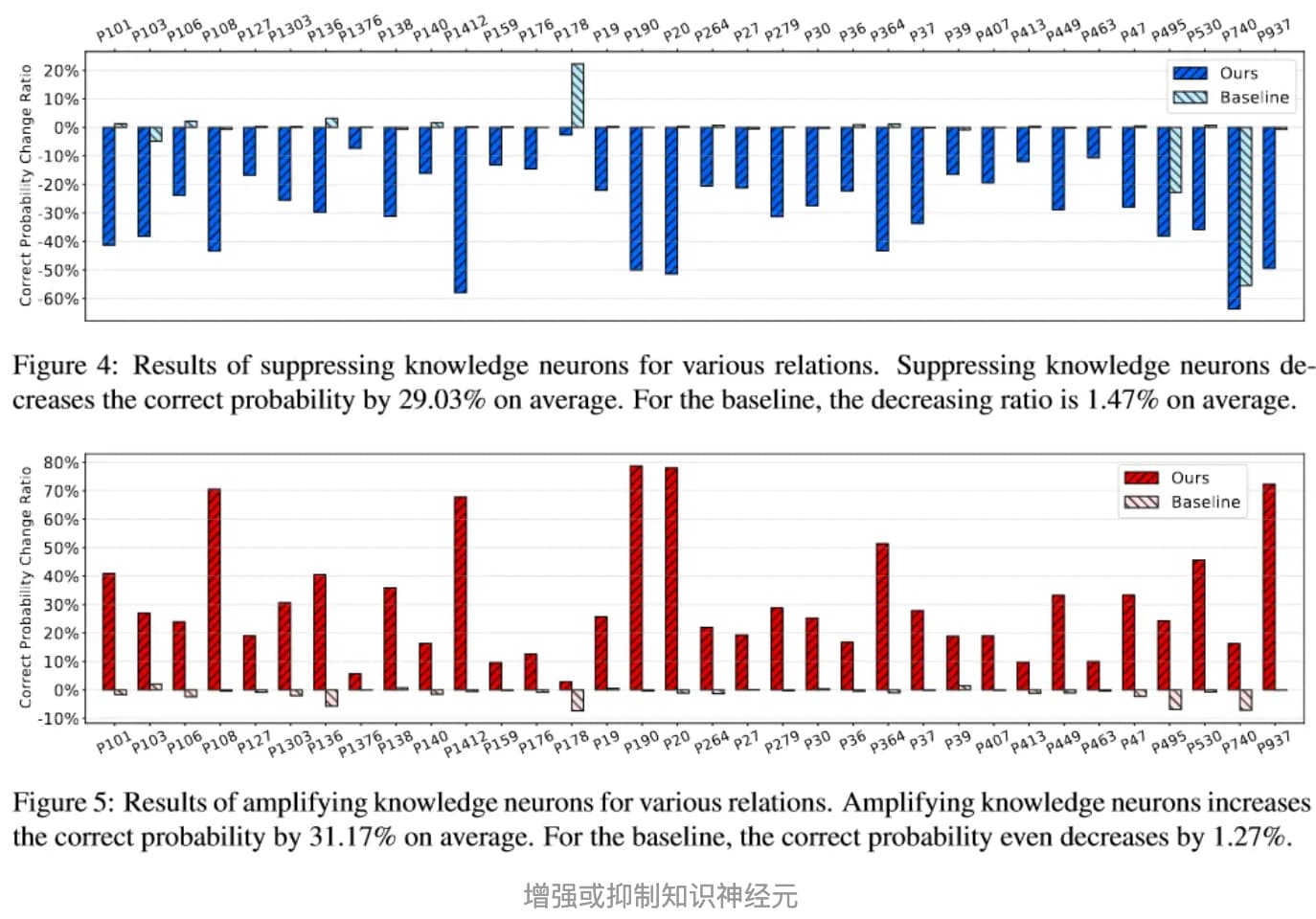
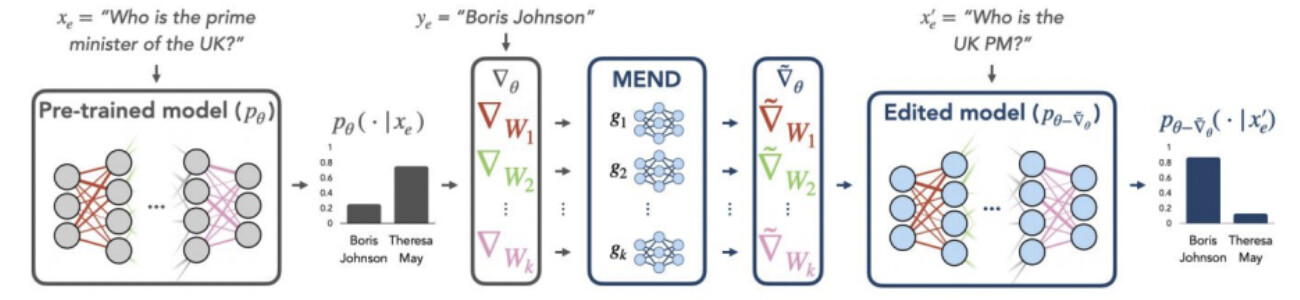
Transformer Feed-Forward Layers Are Key-Value Memories一文指出了FFN的记忆作用,Knowledge Neurons in Pretrained Transformers一文给出了操作知识神经元的应用方式。这些工作对于去除现有语言模型的错误知识,或将新知识注入现有语言模型可能带来帮助。
扩展问题:如何做知识的增强以及改写?
找到旧知识对应的神经元,关闭对应的FFN。
具体操作:
1)使用了积分梯度来归因FFN层和prompt的关系
2)通过编辑FFN的值来调整关系,或者抑制对应FFN的值达到删除关系的结果